Li Kui1, Miguel C. Leon2, Chris Turner3
1 University of California, Santa Barbara, Marine Science Institute
2 University of New Hampshire, Department of Natural Resources and the Environment
3 Axiom Data Science
Introduction
The LTER Network encompasses a diverse community of researchers, information managers, field technicians, and support staff who collectively advance long-term ecological research. Participants across the LTER community engage with various aspects of the research lifecycle, from data collection and analysis to synthesis and communication. These activities span multiple systems and require proficiency in diverse methodologies, programming languages, platforms, workflows, and software tools. Traditionally, most LTER personnel acquired these skills through extensive self-teaching and trial-and-error, with “mastery” taking significant time. Today, Generative Artificial Intelligence (GenAI), especially Large Language Models (LLMs) offers valuable support across the entire research process by automating repetitive tasks, delivering context-aware assistance, reducing time demands, and streamlining workflows. This shift enables LTER participants to dedicate more time to high-value activities such as analysis, creative problem-solving, and scientific discovery, while minimizing technical bottlenecks. GenAI is increasingly used across the research workflow, supporting tasks such as study design and planning, data analysis (e.g., in R or Python), web app and API development, visualization, and software creation. It also aids in brainstorming, hypothesis generation, literature reviews, and preparing presentations, publications, and educational materials.
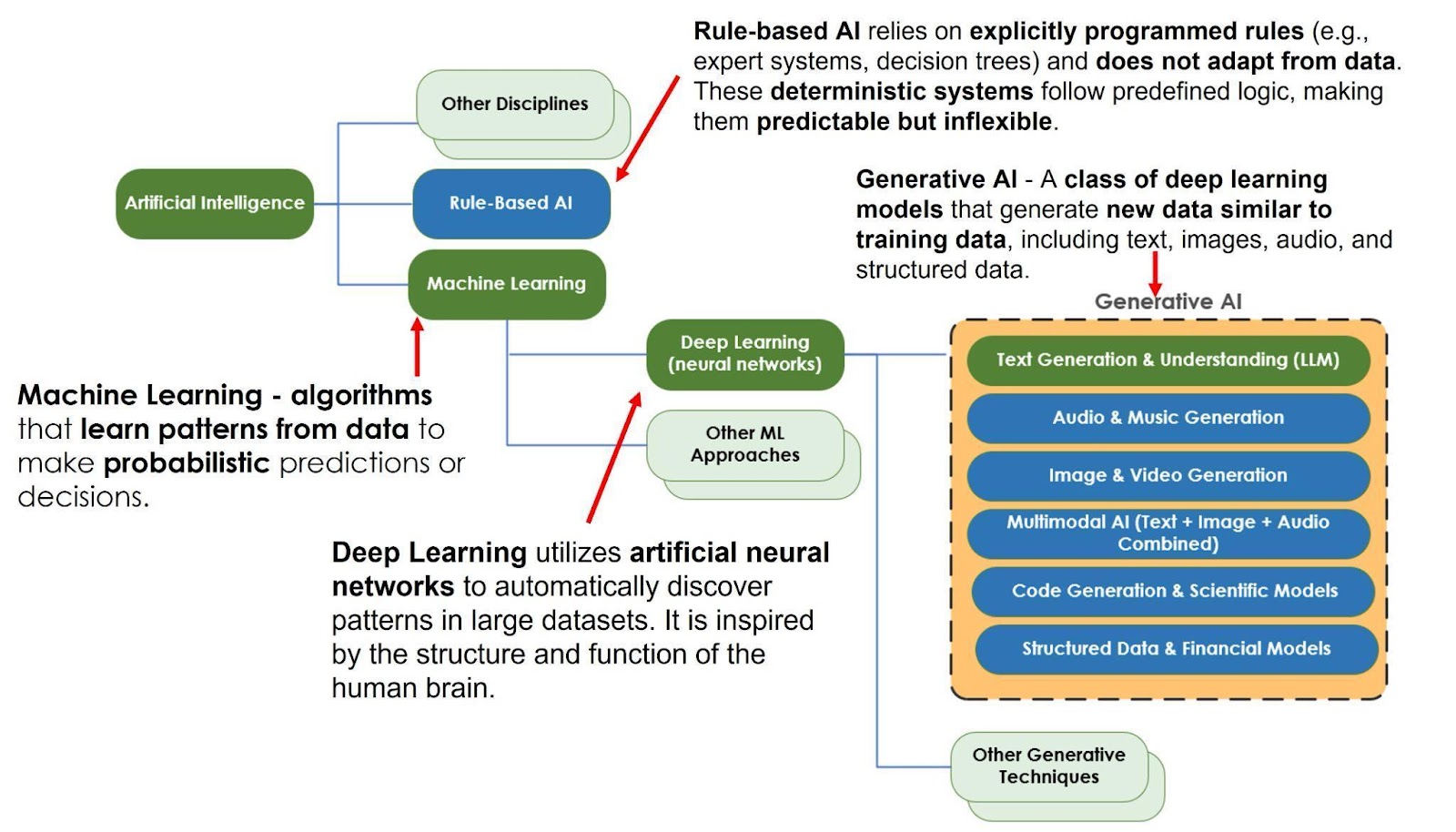
Figure 1. A high-level AI roadmap overview. This figure is modified from Sabado 2025.
GenAI encompasses a range of models capable of creating content across different modalities, including models for generating text from textual prompts (Large Language Models, LLMs), text to images (e.g., DALL-E), text to video (e.g., Sora). An increasingly prominent category is multimodal models, which are trained on diverse data types—such as text, images, and video—and can generate outputs in one or more of these formats (Figure 1). At the core of the GenAI ecosystem are frontier models like ChatGPT, Claude.ai, Google Gemini, as well as specialized applications, typically based on one of the frontier models, like Cursor, GitHub Copilot and Elicit. Frontier models refer to the most advanced, general-purpose models developed by leading AI labs, such as OpenAI, Google, and Anthropic, while specialized tools often tailor these capabilities for specific research or development tasks. All of these models and tools are evolving rapidly, with continual improvements in performance and frequent releases that introduce new capabilities and features. Across different GenAI tools, prompts and workflows are generally transferable, though each tool brings its own unique “flavor” or style, for example, variations in tone, formatting, depth of response, or how they handle specific tasks. Selecting a tool often comes down to individual preference. It is important to approach interactions with GenAI as a dynamic, conversational process rather than expecting a perfect response from a single prompt. Users can iteratively refine their queries—by clarifying, rephrasing, or adding constraints—to achieve more accurate and useful results.
LTER Network participants can leverage GenAI to simplify everyday tasks—such as creating visualizations for presentations, summarizing lengthy emails, troubleshooting software, drafting initial write-ups, or designing logos for projects and research groups. The summary table (Table 1) outlines key research activities where GenAI can add value, including data creation and analysis, data curation, knowledge management, and website/server development. Some of the use cases are paired with specialized tools listed in parentheses. The references listed serve as valuable resources for those interested in delving deeper into the topics discussed. Additional links are provided at the end of the article for further exploration. Together, these examples offer a practical roadmap for integrating GenAI into research workflows to boost efficiency, reduce manual effort, and improve overall productivity.
| Category | How can Generative AI help (Specialized AI-applications) |
| Data Creation and Analysis | Data quality checks, analysis, and visualization (Julius AI and DataLite AI). Data Wrangling and synthesis products (Github Copilot, Codex). Image transcription and species recognition (Amazon Rekognition, Google Vision AI, and PyTorch). |
| Data Curation | Generate metadata and ensure standardization (Custom GPT). Enhance findability, accessibility, interoperability, and reusability of data, the FAIR principles (Cursor AI). |
| Knowledge Management | Summarize content and generate reports (Google NotebookLM). Meeting notes documentation and summary (Adobe Premiere, Read.AI, Otter.AI ). Literature discovery and result organization (Elicit, SciSpace, ChatGPT deep research, and Research Rabbit). |
| Website and Server Construction | Configuring Cloud Compute services. Construct JavaScript that can make user-friendly interfaces. Improve HTML page layout and design (Codia AI HTML Generator). |
- Note, if a specialized AI tool is not mentioned then most GenAI tools can help with this task.
The disadvantages/issues/risks of GenAI
While we find GenAI to be useful in many powerful ways, when used uncritically, GenAI tools present a variety of risks for scientists and society. In this discussion, we divide these risks into three categories: Content Risks, which relate to the material produced by GenAI, Cultural Risks, which concern how GenAI is used and its interaction with cultural ethical and professional norms within the scientific community, and Environmental Risks, which arise from the substantial material and energy demands of GenAI systems, contributing to climate change, biodiversity loss, and freshwater depletion.
Content risks include the currently unavoidable (Hsu, 2025; Xu et al., 2025) and increasingly compelling hallucinations (Editorial Team, 2025) and misinformation (Khatun & Brown, 2023) that GenAI tools will include in responses to user prompts; the perpetuation of biases inherent in the data used to train the model (O’Grady, 2024; SAP Business, 2024; Vicente & Matute, 2023); the potential exposure of sensitive or private information (Obadiaru, 2025; Shanmugarasa et al., 2025); and the simplicity of creating realistic yet artificial data, all while making it increasingly difficult to distinguish between real and AI-generated content (Broadfoot, 2025).
Cultural risks, which might apply to the society at large, are especially concerning for scientists and academics. Such risks include potentially undermining the integrity of scientists and scientific publishing (Conroy, 2023; Kwon, 2025) through the undisclosed use of GenAI for writing (Icamtuf’s thing, 2023), peer review (Chawla, 2024; Naddaf, 2025), and analysis (O’Grady, 2025) complicating and eroding our understanding of plagiarism (Kwon, 2024) while making it easier to accidentally plagiarize other creators (Icamtuf’s thing, 2023); and encouraging uncritical use of and over-reliance on GenAI through growing pressure to adopt these tools, which in turn may limit the scope and creativity of scientific research (Messeri & Crockett, 2024).
In addition to content and cultural risks, GenAI infrastructures/hardware pose significant environmental risks. These include the immense energy demands of training and deploying large models, the associated carbon emissions, especially in fossil-fuel-powered regions, the substantial water usage for data center cooling, and the environmental toll of hardware production and e-waste (Chen et al., 2025; Crawford, 2024).
Mitigating the Risks
Hallucinations and other content risks, despite their prominence in discussions of GenAI in popular media, can be substantially reduced with careful use of the tools and application of information literacy skills. Effective prompt engineering (Greyling, 2023) and response refinement processes like Chain of Verification (Mayo, 2023; Obadiaru, 2025) can help generate responses from LLMs that are more often useful and more likely to be accurate, though even when these techniques have been used the responses should be examined critically and externally confirmed. When using LLMs to develop code, for example, R or Python scripts for a data analysis task, carefully run and review the code to ensure it functions as expected. For general, factual information, verification should leverage external resources to confirm the information provided in LLM responses and to ensure that any sources provided for responses are accurate and sufficiently authoritative. These confirmation steps are fundamental information literacy skills applied to AI. Fortunately, librarians have been writing and teaching about information literacy for decades, and have created helpful guides to information literacy for AI use (UC Irvine Libraries, 2025; University of California Santa Barbara Libraries, 2025; University of North Dakota Libraries, 2025; Willison et al., 2025).
The cultural risks that arise from GenAI use are much harder to address and cannot be directly mitigated by individual user behavior. Publishers, scientific societies, and funders are attempting to address the concerns about how GenAI is transforming scientific research and publishing by creating policies and standards for how GenAI can be used and how that use should be transparently communicated (Ecological Society of America, 2025; National Institutes of Health, 2025; Purdue University Libraries and School of Information Studies, 2025; Stall et al., 2023), but it remains to be seen what effects these policies have on the adoption and use of GenAI.
Numerous strategies have been proposed to mitigate the environmental impacts of GenAI, including advances in hardware and algorithmic efficiency, improved training optimization, and the use of renewable energy in data centers (U. S. Government Accountability Office, 2025; UN Environmental Programme, 2024). Additionally, emerging research across the broader AI/ML field offers promising avenues for developing more efficient methods that could help address the technical challenges of reducing AI’s environmental footprint (Schwartz et al., 2019).
What’s next in GenAI use
Current frontier models push the limits of performance, streamlined versions—like OpenAI’s o4-mini, Google Gemini, and DeepSeek—offer faster, resource-efficient alternatives that can run locally on modern laptops and be fine-tuned with LTER-specific knowledge. Models increasingly support longer context windows, allowing for more seamless conversations without repeated inputs. They also feature advanced reasoning techniques, such as chain-of-thought, enabling them to break down complex tasks and build complete applications directly from a prompt. Agentic AI, can interact with APIs, query databases, and design and execute complex code simultaneously. This enables it to handle sophisticated tasks like: “Extract fire history data from 2000–2024 from the SQL database, use the manuscript to generate a FAIR-standard EML, publish the data package to EDI, and provide the data citation.” It can also respond to simpler prompts, such as: “Show me how many datasets we published in 2024 on EDI.” For those interested in where the generative industry thinks they are headed, a good place to start is Machines of Loving Grace (Amodei, 2024). Here they discuss how they hope to create a compressed 21st century with, among other desirable outcomes, a century’s worth of advances in biology and medicine in 5 to 10 years.
As GenAI continues to evolve, use cases can be expected to rapidly expand beyond those covered in this article. We encourage members of the LTER Network to thoughtfully explore how GenAI tools can be responsibly integrated into their workflows today. Building familiarity with these tools, along with an understanding of their strengths and limitations, will better prepare researchers to adopt and effectively use new AI technologies as they emerge.
Acknowledgement: We are especially grateful to John H. Porter, Hillary Krumbholz, Marina Frants, Gabriel De La Rosa, and Marty Downs for their valuable contributions to both the content structure and English language editing, which greatly enhanced the quality of this manuscript.
Data Creation and Analysis
Quality check, analysis and visualization
GenAI is highly effective for data quality checking and analysis, either by directly generating results or providing scripts to complete tasks. For example, when analyzing the abundance of 100+ marine species to assess whether the species have been increased or decreased over time, GenAI can present results as a high-level summary and detailed outputs per species, complete with visualizations (Figure 2, Table 2). Users can also request intermediate tables and figures for quality control and diagnostics.
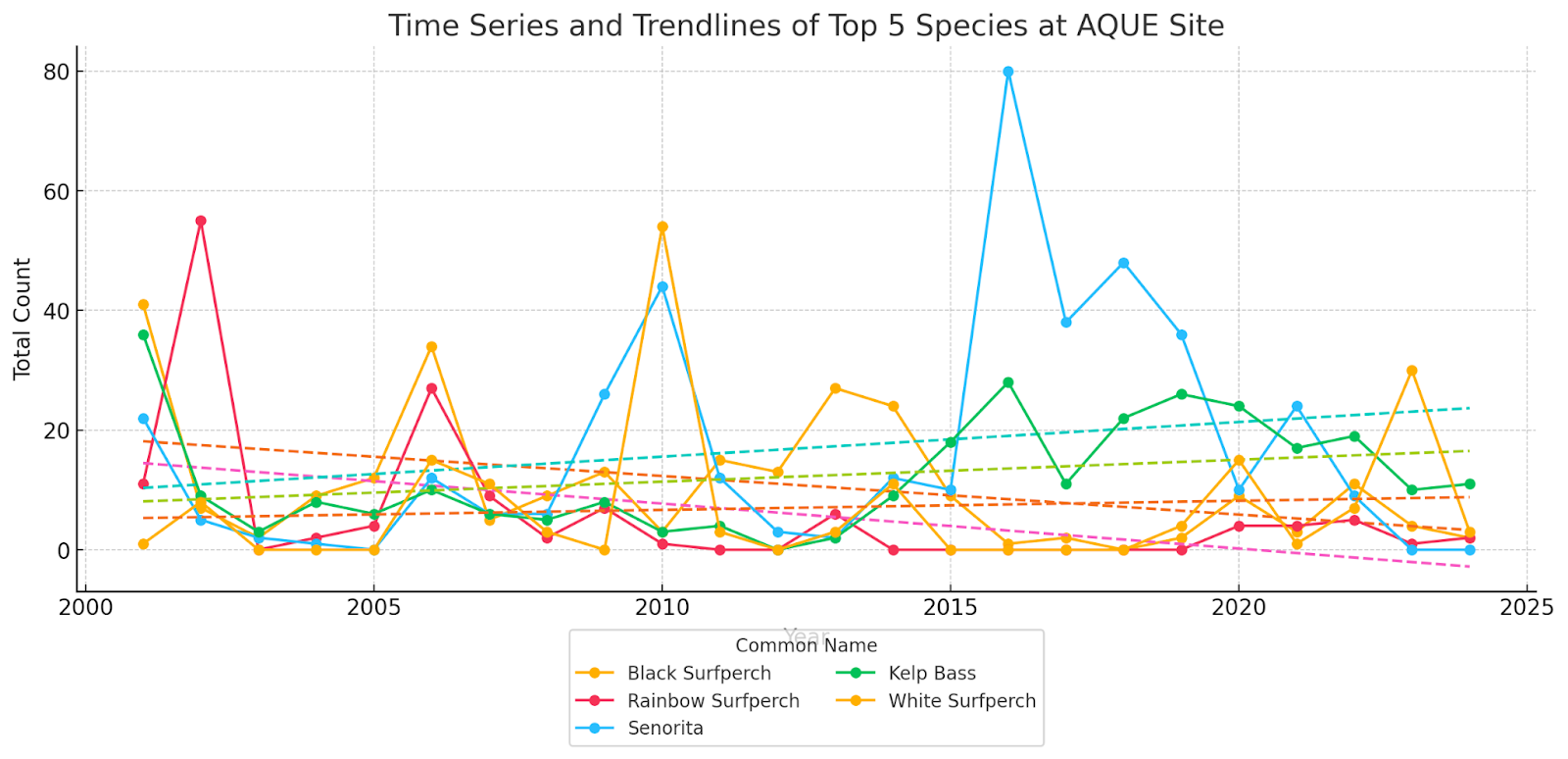
Table 2, ChatGPT output of the summary table. Linear regression results showing temporal trends in abundance for the five most common fish species at the Arroyo Quemato site. Each model evaluates whether species count has changed significantly over time (Year as predictor). Coefficients indicate direction and magnitude of change, with p-values assessing statistical significance.
| Common Name | Coefficient (Year) | Intercept | R-squared | p-value (Year) |
| Black Surfperch | -0.645 | 1308.333 | 0.179 | 0.039 |
| Rainbow Surfperch | -0.751 | 1517.833 | 0.196 | 0.030 |
| Senorita | 0.579 | -1148.500 | 0.043 | 0.332 |
| Kelp Bass | 0.367 | -725.333 | 0.076 | 0.192 |
| White Surfperch | 0.152 | -298.333 | 0.008 | 0.685 |
Additionally, GenAI can generate code for custom analyses and visualizations. For enhanced data visualization, GenAI can assist in developing R scripts that construct Shiny apps to display relevant figures and results. For example, an analysis conducted in Python or Matlab could produce 100 text files to a “results” folder, and 30 figures to a “figures” folder; one can `ls` (list) the file paths and use GenAI to help develop a Shiny App to serve these contents. Through the use of GenAI, more robust and user-friendly Shiny Apps can be developed much more quickly to read the data from the server and generate feature-rich outputs, such as time series graphs, box plots, summary statistical information, and model results, which significantly accelerates data exploration and visualization. For research purposes, many data-analysis AI-powered tools have emerged, such as Julius AI and DataLite AI. These tools allow researchers to upload datasets and run analyses based on specific research questions or instructions, which shortens the data exploration phase.
GenAI streamlines the refinement of visualizations, making it faster and more efficient to achieve the desired results. Generating Matplotlib plots in R or Python can be time-consuming and challenging, but GenAI simplifies the process by allowing users to input existing code and request improvements tailored to their visual goals. Iteration is still an essential part of this workflow but results can be achieved much faster than manually searching for solutions on Stack Overflow or other coding sites. AI generated code is displayed in the browser, ready to be copied into a local IDE for execution and further refinement. When GenAI is used in visualization fine-tuning, results are achieved more quickly and the process leads to more effective and visually appealing data representations.
Data Wrangling and synthesis products
In the process of data wrangling, Github CoPilot or OpenAI Codex, AI-tools set up within an Interactive Development Environment (IDE), can improve the efficiency of boilerplate code. For example, when mapping columns of data between datasets for munging, synthesis, or to change formats or units, CoPilot can provide code suggestions based on any analysis requests or description comments in the document prior to the code chunk (pseudocode). If a dataset has already been used and a transformation is applied to one column, Copilot can anticipate similar operations on the next column and automatically suggest the corresponding code. Then, simply hitting the tab key completes the line. This can save a lot of time and typing, improving workflow efficiency. This has been used to great effect in, for example, The Luquillo LTER signature dataset.
To ensure the reproducibility of synthesized data products, we use GenAI as an initial tool for data munging while maintaining thorough documentation of the programming scripts. When combining multiple, heterogeneous data files, a typical workflow begins by uploading individual data tables, or samples of tables with large datasets, into the AI tool and request it to subset, standardize units, check taxonomic information, and restructure the data into a common format. These individual files are then concatenated into a consolidated dataset. Throughout this process, the AI tool generates scripts for each step, ensuring that the entire workflow is transparent, reproducible, and well-documented. This approach not only streamlines data processing but also facilitates consistency and traceability in data synthesis.
Image transcription and species recognition
Historical documents hold valuable scientific insights, but much of this information remains locked away in non-digital formats. These materials—ranging from personal diaries with observations of daily life to handwritten field notebooks—offer unique perspectives on the natural world and past events. While optical character recognition (OCR) works well for typed text, it falls short when applied to even the neatest handwritten pages. AI now offers a powerful alternative: by uploading photos or scans of handwritten documents, users can request verbatim transcriptions. Although the results require careful proofreading, this semi-automated approach reduces the need for manual typing, limits handling of fragile originals, and can often decipher messy handwriting better than human transcribers. For large-scale projects, APIs like the OpenAI API allow for bulk processing. As more historical content is transcribed and digitized, hidden insights and long-forgotten details become accessible and searchable, unlocking new opportunities for research and discovery.

AI-powered image recognition tools are increasingly being used for research, with options including Amazon Rekognition, Google Vision AI, and PyTorch. Amazon Rekognition specializes in object detection, making it valuable for tracking species or identifying specific objects in various environments (e.g., plastic pollution in the ocean). Google Vision AI offers robust cloud-based image classification, great for spatial analysis using drone or satellite imagery. PyTorch, a flexible deep-learning framework, allows researchers to develop and train custom AI models for more complex image analysis tasks. Although the inner workings of these AI-powered image tools remain somewhat opaque, they undeniably improve efficiency across a wide range of research applications.
Data Curation
EML generation and standardization
GenAI can facilitate EML generation through assisting in creating structured template files intended for integration into established metadata management systems. Researchers begin by uploading data tables, methodological descriptions, and abstracts associated with a data package. GenAI extracts key information—such as column headers—and automatically generates corresponding content, like column descriptions, by referencing the methods and abstract. This information is then inserted into a pre-defined template (e.g., one provided by the site Information Manager), which can be directly integrated into an existing metadata system. This process has significantly streamlined the preparation of EML files.
In addition, GenAI can use metadata and data tables provided by researchers to produce a simplified version of an EML document. GenAI can generate a valid EML file based on the provided data. However, this initial version is a simplified EML that may lack key nodes required to meet LTER metadata standards, necessitating further refinement. Although this can serve as a strong starting point, additional work is needed. By supplying additional information, such as project boilerplate documents, GenAI can generate a more complete and standardized EML. Additionally, when annotating units with QUDT standards in an EML document (Porter 2025), GeAI can identify the appropriate QUDT units and generate the corresponding <annotation> tags, which can then be added to the EML file to further enhance metadata quality and interoperability.
If work involves repetitive tasks, such as building EML files (without an existing system to do so) or updating datasets, it may be beneficial to create a customized GPT tool (only available in the paid version). A tailored model can automate routine data formatting and transformation tasks, generate standardized reports or metadata files, and streamline data validation and quality checks. These customized GPTs were trained on specific workflows and documentation, enabling them to efficiently manage tasks that follow structured procedures and logical processes.
FAIR Data
In the LTER Information Management community, much of our work is centered on aligning site data and metadata with the FAIR Principles. These principles are aimed at making data Findable, Accessible, Interoperable, and Reusable, with an emphasis on the need for machine-readability achieved through the creation of rich, accurate, and relevant metadata; the use of globally unique and resolvable identifiers wherever possible; and adherence to formal, accessible, and community-relevant standards. Much of what these principles require is already achievable using the common LTER Information Management standards (EML metadata), resources (EDI, EML generation tools), and community best practices, but the discussion and examples above suggest some of the ways that GenAI could make it easier to create or improve workflows for generating FAIR data and metadata (Ma et al., 2024)
Findable – We have mentioned using GenAI to add identifiers for QUDT units to an EML record as annotations. However, we see space for GenAI to help create or enrich metadata content before generating the formal EML representation. For example, GenAI could be used to review site reports and publications to suggest keywords, taxa, people, and organizations from vocabularies or taxonomies that follow FAIR principles. Similarly, GenAI could be used to compare components of existing metadata records to peer-reviewed publications and other relevant documents to identify potentially relevant data sources or methods not already listed in the metadata.
Accessible – In the FAIR Principles, accessibility requires that data are retrievable through their identifier using standard, open, and free communication protocols (i.e., http, ftp, etc.). Most LTER sites achieve this through the use of the EDI repository and GitHub, but sometimes bespoke services are needed. GenAI, specifically AI coding assistants, such as Cursor AI, can help with the technical challenges of spinning up Shiny apps, APIs, or web services (see the Website and Server Construction section, below).
Interoperable data are those that can be reliably integrated with other datasets or into applications or workflows; this requires a formal and accessible representation, the use of terms from FAIR vocabularies, and qualified references to other data and metadata. The XML schema for EML is the formal knowledge representation for LTER site metadata, and we have discussed above some of the ways that GenAI can be used to help prepare EML. However, we do not have a similarly uniform representation of data across sites, though there have been efforts to create something like this for certain data types in the past, for example in ClimDB, HydroDB, and then with CUAHSI, and many sites have biological data that would be valuable to more researchers if formatted in Darwin Core and published in OBIS and GBIF. We see opportunities to use GenAI to help convert some site data into these and other shared, formal representations using some of the same techniques discussed in the sections on EML generation and data wrangling, above.
Reusable data depends on rich metadata that describes the dataset, its license, and its provenance in standards relevant to the relevant communities. This information must be understandable to the people and machines that will interpret and potentially reuse the data and metadata. There are many opportunities right now to use GenAI to help enrich our metadata, for example: summarizing sampling plans and methods, assessing the relevance of documents for inclusion as references in our EML, or to compare methods described in those documents to check for new or different processes not described in the metadata. Finally, when metadata is needed in a standard other than EML, for example, CF-compliant netCDF files for model results or time-series of remote sensing data, GenAI can create the templates and crosswalks for moving metadata and data between standards.
Knowledge Management
Managing and Understanding Meeting documents with GenAI
GenAI is increasingly used to streamline meeting preparation and documentation. Meeting organizers often prepare or provide significant amounts of background materials for a meeting. These can be loaded into tools such as Google NotebookLM where a meeting participant can get quick summaries of each document and ask specific questions about them. This can help make it easier and faster to comprehend the materials provided. NotebookLM can also summarize what all materials have to say about a particular subject or answer simple questions like the address of the meeting and the start time. GenAI makes finding relevant information faster. Notes from the meeting can be added and then interrogated regarding their relationship to the background information. With appropriate notification (such as the in-meeting alerts shown by Zoom), GenAI can be used to create meeting transcripts. These transcripts can then be imported into NotebookLM, where users can request summaries by topic or identify what specific individuals said about a given subject. This integration enhances the documentation and accessibility of meeting outcomes.
Post meeting notes and documentation
For the Information Management committee annual report, we have used Adobe Premiere, a video editing tool with several AI features built in, to transcribe all talks and document them in the report. In addition, we used GenAI to summarize the transcriptions, leaving very little editing necessary. Previously, this was a process that would take the Information Management executive board multiple days to complete. Now, it is almost 90% done by running through GenAI and the transcripts only need to be read through for accuracy. We recently learned about another AI-powered tool, READ.AI, which is a meeting assistant designed to enhance productivity by recording a meeting (with all participants’ permission), automatically transcribing, summarizing, and analyzing virtual meetings. The tool integrates well with popular video conferencing platforms, such as Zoom. In addition, multimodal models that process voice and video can provide feedback on speaker content, engagement, or presentation style. Google is developing new features for YouTube search that will soon allow users to locate specific segments within a longer video. For example, in a video recording of a meeting with multiple speakers, it will be possible to search for a particular speaker and be directed to the segment where that person begins their talk.
Literature review
Tools such as Elicit, SciSpace, ChatGPT Deep Research, and Research Rabbit transform the way we discover, analyze, and synthesize scientific literature. In the earlier versions of the GenAI, if they were asked to explain some ecological theory with a citation, the response could be a book or papers that don’t exist (often referred to as hallucinations). The recent literature review tools that incorporate the AI feature have limited their search space to within the known scientific databases. They provide accurate sources and can perform follow-up actions (e.g., summarize or analyze the content). Elicit automates literature reviews by extracting key findings, summarizing papers, and suggesting relevant sources. SciSpace helps users comprehend complex scientific texts by explaining concepts and highlighting key information, and can interact with users to address specific questions related to a particular paper. ChatGPT Deep Research can perform tasks similar to Elicit and SciSpace. Research Rabbit enables visual exploration of literature, creating interactive citation maps that reveal connections between papers and lay out the timeline of all papers. ChatGPT-4o, as a GenAI tool, has significantly enhanced its ability to search and summarize literature. However, as of now, it still gathers information from various publicly available websites, so its responses may not be exclusively based on peer-reviewed papers. Together, these tools streamline the research process, improve literature discovery, and support more efficient knowledge synthesis.
Website and Server Construction
Configuring Cloud Compute services
GenAI simplifies the process of deploying REST APIs and server-side services on cloud infrastructure. They can assist in mapping database structures to data standards—such as generating SQL materialized views based on the desired format—and offer guidance throughout the API deployment process. For example, when setting up tools like PostgREST for a PostgreSQL server, GenAI can provide step-by-step instructions on downloading, configuring the server, editing settings, and opening ports. This makes complex backend setup tasks more efficient and accessible, even for users with limited experience.
Construct JavaScript that can make user-friendly web interfaces
For managing websites, GenAI can be a valuable resource for building functional JavaScripts. Essentially, GenAI can assist in creating JavaScript that enables a website to communicate with APIs to databases and retrieve the necessary information. Several cases from the LTER community demonstrate how GenAI has been used for JavaScript development:
a) Retrieving species status and taxonomic information via the WoRMS API.
Prompt: I have a list of aphiaID values from WoRMS. Write code for a static HTML web page which accepts a list of aphiaID values in a text box (each value on its own line). When the user clicks a button that says “Check WoRMS”, JavaScript code should check each aphiaID in WoRMS to determine its status. It should then write the result to the web page with these columns: AphiaID, Name, Status, Accepted_ID, Accepted_Name.
Environment: ChatGPT, April 2024. See BLE website.
b) Supply a DOI and ask a GenAI to format and display the full citation of a paper using Crossref API.
Prompt: I have a list of article DOIs. Write code for a static HTML web page which accepts a list of DOIs values in a text box (each value on its own line). When the user clicks a button that says “Check publication”, JavaScript code should check each DOIs in CrossRef and output the bibtex for all the articles. Then there is a bottom that allows users to download the bibtex file.
Environment: ChatGPT, May 2024.
c) GenAI can also help fetch data from NOAA or NASA APIs and generate visualizations directly on websites.
Prompt: Generate a html page with JavaScript that fetches tide data from NOAA’s Tides and Currents API for a specific station and displays the data using a line chart. The begin_date is yesterday and end_date is 2 days from now. Highlight the current time with a red line. Please include a date adapter. This is an example: product=predictions&application=NOS.COOPS.TAC.WL&begin_date=20240904&end_date=20240907&datum=MLLW&station=9411340&time_zone=lst_ldt&units=english&interval=hilo&format=json
Environment: ChatGPT, Aug 2024. See the second figure on the SBC website.
Improve HTML page layout and design
For those wanting to enhance websites without HTML familiarity or uncertainty about modern design options, GenAI can generate images of potential website layouts, allowing users to choose styles that suit specific needs. Once a design has been selected, GenAI can modify website HTML to match the exact requested layout. Some recently developed tools such as Codia AI HTML Generator will be worth trying. Website owners no longer need to be webmasters to update and refine their websites.
Resources
- Github Copilot free version for educators and students: https://docs.github.com/en/copilot/managing-copilot/managing-copilot-as-an-individual-subscriber/getting-started-with-copilot-on-your-personal-account/getting-free-access-to-copilot-pro-as-a-student-teacher-or-maintainer
- A visualization of major large-language models (LLMs): https://informationisbeautiful.net/visualizations/the-rise-of-generative-ai-large-language-models-llms-like-chatgpt/
- Heidt, Amanda. AI for research: the ultimate guide to choosing the right tool. Nature 640, 555–557 (2025). https://doi.org/10.1038/d41586-025-01069-0
References:
Amodei, D. (2024, October). Machines of Loving Grace. https://www.darioamodei.com/essay/machines-of-loving-grace
Broadfoot, M. (2025, April). Synthetic data created by generative AI poses ethical challenges. National Institute of Environmental Health Sciences. https://factor.niehs.nih.gov/2025/4/feature/ai-data-ethics
Chawla, D. S. (2024). Is ChatGPT corrupting peer review? Telltale words hint at AI use. Nature, 628(8008), 483–484. https://doi.org/10.1038/d41586-024-01051-2
Chen, Q., Wang, J., & Lin, J. (2025). Generative AI exacerbates the climate crisis. Science, 387(6734), 587–587. https://doi.org/10.1126/science.adt5536
Conroy, G. (2023). How ChatGPT and other AI tools could disrupt scientific publishing. Nature, 622(7982), 234–236. https://doi.org/10.1038/d41586-023-03144-w
Crawford, K. (2024). Generative AI’s environmental costs are soaring—And mostly secret. Nature, 626(8000), 693–693. https://doi.org/10.1038/d41586-024-00478-x
Ecological Society of America. (2025). Artificial Intelligence (AI) Policy – Publications. https://esa.org/publications/artificial-intelligence-ai-policy/
Editorial Team. (2025, May 6). Smarter AI, Riskier Hallucinations Emerging. Artificial Intelligence +. https://www.aiplusinfo.com/smarter-ai-riskier-hallucinations-emerging/
Greyling, C. (2023, August 2). 12 Prompt Engineering Techniques. Medium. https://cobusgreyling.medium.com/12-prompt-engineering-techniques-644481c857aa
Hsu, J. (2025, May 9). AI hallucinations are getting worse – and they’re here to stay. New Scientist. https://www.newscientist.com/article/2479545-ai-hallucinations-are-getting-worse-and-theyre-here-to-stay/
Icamtuf’s thing. (2023, May 15). LLMs and plagiarism: A case study [Substack newsletter]. Lcamtuf’s Thing. https://lcamtuf.substack.com/p/large-language-models-and-plagiarism
Khatun, A., & Brown, D. (2023). Reliability Check: An Analysis of GPT-3’s Response to Sensitive Topics and Prompt Wording. In A. Ovalle, K.-W. Chang, N. Mehrabi, Y. Pruksachatkun, A. Galystan, J. Dhamala, A. Verma, T. Cao, A. Kumar, & R. Gupta (Eds.), Proceedings of the 3rd Workshop on Trustworthy Natural Language Processing (TrustNLP 2023) (pp. 73–95). Association for Computational Linguistics. https://doi.org/10.18653/v1/2023.trustnlp-1.8
Kwon, D. (2024). AI is complicating plagiarism. How should scientists respond? Nature. https://doi.org/10.1038/d41586-024-02371-z
Kwon, D. (2025). Science sleuths flag hundreds of papers that use AI without disclosing it. Nature, 641(8062), 290–291. https://doi.org/10.1038/d41586-025-01180-2
Mayo, M. (2023, October 17). Unlocking Reliable Generations through Chain-of-Verification: A Leap in Prompt Engineering. https://www.kdnuggets.com/unlocking-reliable-generations-through-chain-of-verification
Messeri, L., & Crockett, M. J. (2024). Artificial intelligence and illusions of understanding in scientific research. Nature, 627(8002), 49–58. https://doi.org/10.1038/s41586-024-07146-0
Naddaf, M. (2025). AI is transforming peer review—And many scientists are worried. Nature, 639(8056), 852–854. https://doi.org/10.1038/d41586-025-00894-7
National Institutes of Health. (2025, February). Artificial Intelligence in Research: Policy Considerations and Guidance. Office of Science Policy. https://osp.od.nih.gov/policies/artificial-intelligence/
Obadiaru, A. (2025, April 25). LLM Data Leakage: 10 Best Practices for Securing Large Language Model.
O’Grady, C. (2024, August 28). AI makes racist decisions based on dialect—Large language models strongly associated negative stereotypes with African American English. https://www.science.org/content/article/ai-makes-racist-decisions-based-dialect
O’Grady, C. (2025, May 14). Low-quality papers are surging by exploiting public data sets and AI. https://www.science.org/content/article/low-quality-papers-are-surging-exploiting-public-data-sets-and-ai
Purdue University Libraries and School of Information Studies. (2025). Artificial Intelligence (AI): Publisher Policies and Requirements. https://guides.lib.purdue.edu/c.php?g=1371380&p=10135076
SAP Business. (2024, October 29). What is AI bias? https://www.sap.com/resources/what-is-ai-bias
Schwartz, R., Dodge, J., Smith, N. A., & Etzioni, O. (2019). Green AI (arXiv:1907.10597). arXiv. https://doi.org/10.48550/arXiv.1907.10597
Shanmugarasa, Y., Pan, S., Ding, M., Zhao, D., & Rakotoarivelo, T. (2025). Privacy Meets Explainability: Managing Confidential Data and Transparency Policies in LLM-Empowered Science (arXiv:2504.09961). arXiv. https://doi.org/10.48550/arXiv.2504.09961
Stall, S., Cervone, G., Coward, C., Cutcher-Gershenfeld, J., Donaldson, T. J., Erdmann, C., Hanson, R. B., Holm, J., King, J. L., Lyon, L., MacNamara, D. P., McGovern, A., McGranaghan, R., Narock, A. A., Parker, M. S., Peng, G., Rao, Y. “Douglas,” Ryan, E., Sedora, B., … Participants, A. A. E. W. (2023). Ethical and Responsible Use of AI/ML in the Earth, Space, and Environmental Sciences. https://doi.org/10.22541/essoar.168132856.66485758/v1
U. S. Government Accountability Office. (2025, April 22). Artificial Intelligence: Generative AI’s Environmental and Human Effects. https://www.gao.gov/products/gao-25-107172
UC Irvine Libraries. (2025, March 21). Generative AI and Information Literacy. https://guides.lib.uci.edu/gen-ai/info-literacy
UN Environmental Programme. (2024, September 21). AI has an environmental problem. Here’s what the world can do about that. https://www.unep.org/news-and-stories/story/ai-has-environmental-problem-heres-what-world-can-do-about
University of California Santa Barbara Libraries. (2025). LibGuides: AI and Academic Use: AI and Academic Publishing. https://guides.library.ucsb.edu/c.php?g=1414147&p=10844924
University of North Dakota Libraries. (2025, June 5). Artificial Intelligence: AI literacy as Info Literacy. https://libguides.und.edu/c.php?g=1335774&p=9865889
Vicente, L., & Matute, H. (2023). Humans inherit artificial intelligence biases. Scientific Reports, 13(1), 15737. https://doi.org/10.1038/s41598-023-42384-8
Willison, S., Leech, G., Sotala, K., & Kaufman, J. (2025, April 24). Best Practices for Large Language Models. https://guides.library.cmu.edu/LLM_best_practices/home
Xu, Z., Jain, S., & Kankanhalli, M. (2025). Hallucination is Inevitable: An Innate Limitation of Large Language Models (arXiv:2401.11817). arXiv. https://doi.org/10.48550/arXiv.2401.11817