Appreciating the history, work, and future of LTER’s data repository, the Environmental Data Initiative.
by Tommy Shannon
Democratizing Data

Credit: Image created with BioRender.com
Data is the lifeblood of research. Data quantifies, illuminates, transmits, and stores the facts of life we gather in the ecosystems we cherish. Indeed, the founding philosophy of the Long Term Ecological Research Network (LTER) is that through the development of long term datasets we may gain a greater vantage point to view the true nature of nature. Yet our hard-earned ecological data can too easily become “dark data,” stashed away in filing cabinets and old hard drives until it molds away, used maybe once. To combat dark data, digital online databases have been established to preserve and re-use data for decades to come.
The data generated through LTER funded research is stored or referenced in the Environmental Data Initiative (EDI). EDI started life as an LTER-specific data repository in 2013, and has since expanded to become its own entity for curating, safekeeping, and serving environmental data in general. The repository’s founding purpose was to make data publicly available for common benefit; to fulfill this mission, EDI became an early adopter and champion of FAIR (Findable, Accessible, Interoperable, and Reusable) data practices. A new paper reflects on the database’s use, its adherence to the FAIR principles, and its vision for the future of environmental data use, one decade after the start of EDI.
Building a FAIR data repository: Meet Dr. Gries
Dr. Corinna Gries, co-director of the EDI and lead author of the new paper, is a founder and early leader of digital database development. She championed the digitization of LTER and natural history data, and has been at the helm of EDI since its creation. Her passion and vision for environmental information management have shaped the way environmental data is stored far beyond the LTER.

Credit: UW Madison Center for Limnology
According to Dr. Gries, the motivation for EDI to embrace the FAIR data principles comes from LTER’s history: “The long term monitoring data from LTER sites are gathered [collectively], so those datasets don’t belong to a person; they belong to a site. Therefore, the site is responsible for documenting its data well enough to ensure that anybody coming to the site can use it.” As people outside an LTER site begin to use that data too, there is even more need to document data in a way that enables informed data use. Thus, the use of FAIR principles helps ensure that data remains a commonly held and commonly used resource—a world heritage.
In practice, adherence to the FAIR principles requires that data submitted to EDI is accompanied by sufficient metadata. Metadata is information about data, like: Where and when did you collect those fish? What methods and instruments were used to measure carbon flux? What categories does your research on the socio-economic impact of invasive species fall under? This supplementary information enables other researchers to find and use our data in an informed manner. As Dr. Gries puts it, “These valuable long-term datasets deserve to be documented in such a way that anybody can pick them up and use them.”
Wrangling the data: How are we doing?
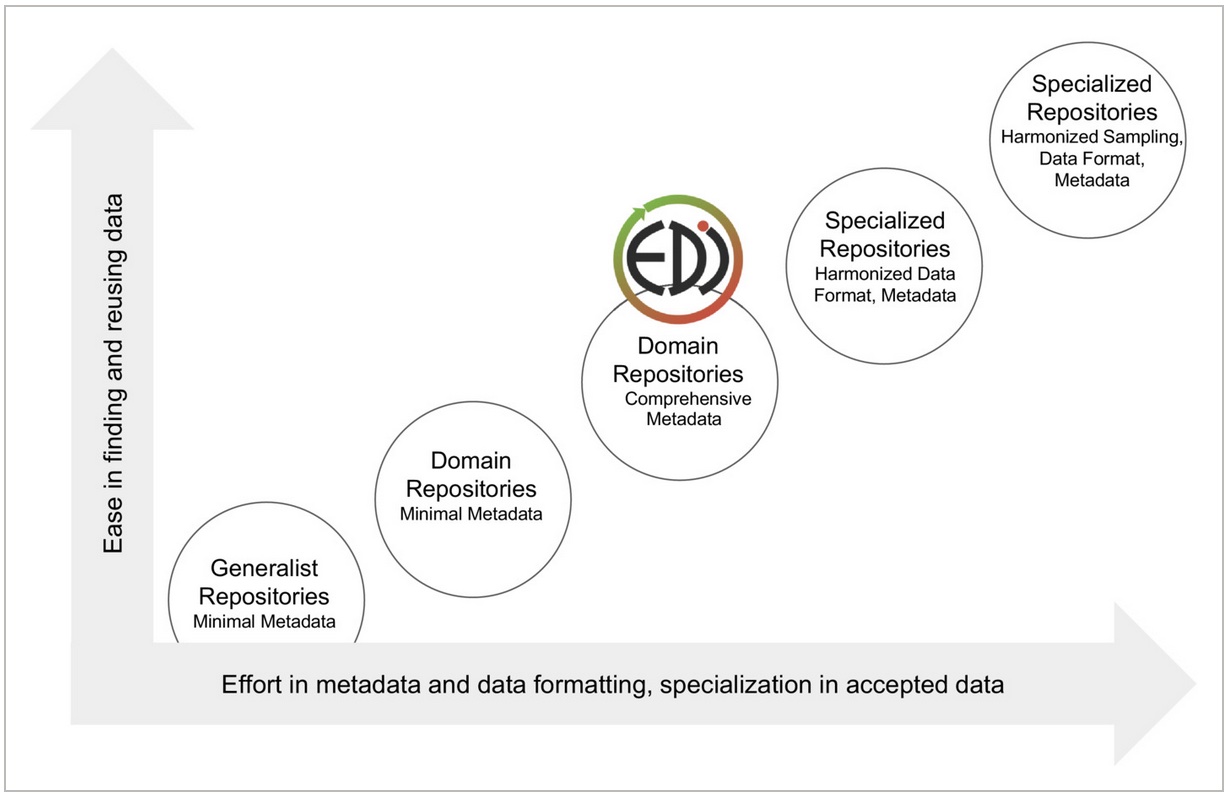
Credit: Printed with permission, from Gries et al. 2023
The issue with developing robust metadata criteria for environmental data is that these datasets take so many different forms and include such an incredible diversity of information that it becomes difficult to document it all in a standardized way. A balancing act begins: if EDI requires high data uniformity or lots of metadata, it may exclude valuable datasets which are unable to meet those stringent requirements or fall outside of its parameters—especially damaging for historically important datasets created before these standardized practices. On the flip side, if EDI loosens its formatting and metadata requirements too much, datasets may become unfindable or unusable if not enough information is available. EDI’s solution has been to find a “goldilocks zone” for data inclusivity (Fig. 1), and to develop tools like customizable metadata templates and the guiding application “ezEML,” which make it clear and easy to create flexible yet in-depth metadata.
In their decadal review, Gries et al. assess how well EDI adheres to FAIR principles by reviewing how well its submitted metadata abides by 46 attributes of FAIR data use (i.e., does metadata have keywords? Is measurement precision defined?). They found that across all categories, EDI maintains a remarkably high adherence rate for almost all FAIR attributes. When asked about the few attributes with low adherence, Dr. Gries was confident that it’s just a matter of time before these increase too—some digital data practices are just catching on, and the younger generation of tech savvy scientists will vitalize these new standards.
The other successes of EDI are abundant: Over 30% of EDI datasets include at least a decade of data. EDI datasets have been cited over 2,500 times, and data citation is increasingly more common. In 2021 alone, 180,000 requests were made for data. But according to Dr. Gries, “the most amazing example [of EDI’s success] is all these ecological community observations. I think it’s the first time in history that… ecological datasets of communities and populations have been documented in a consistent way for decades. EDI has been supporting all of this [LTER research], building tools to help document this research, and encouraging FAIR practices and good metadata submission.” She added, “Doing all this data management is a lot of work, and we have to recognize that.”
So how can each of us support this endeavor?
- Take the time to carefully create metadata for our datasets. A decade (or even a year) of data deserves an hour of our time to properly document. Doing so ensures that our data will live on, empowers other projects, and boosts our data citations. (A tip: documenting metadata as early as possible will make the process easier and reduce uncertainty!)
- Cite the data we use, both our own and others! All EDI data packages have unique identifiers (DOIs) just like publications. Citing data is easy, gives credit, provides insight on data use, and makes data more visible.
- Talk to your data managers. They have excellent insights and advice on how to approach data documentation and submission, and are happy to provide guidance on how to develop datasets in ways that ensure their integrity, longevity, and FAIRness.
- Consider earmarking support for data management in large grants. Just as field work and facilities require hard work and funding, so does data storage and management.
Collecting and sharing data underpins initiatives designed to protect the ecosystems we love. From understanding climate change trends to developing AI-based big data analysis, the future of ecology relies on the contributions and maintenance we provide for our ecological database. Dr. Gries is retiring soon, so it is up to the rest of us to carry on her standard of good data management.
Thank you, Dr. Gries, and thank you to all of the incredible people who have worked hard to shape and maintain the data that support us all.









